AI adoption inside companies is happening from the bottom up. A company gives employees access to Claude, Codex, Cursor, ChatGPT, or some mix of them, and people immediately start building their own ways of working. One person connects an agent to Salesforce. Another writes a reusable prompt for weekly account research. An engineer gives a coding agent repo context. Someone else creates a Slack workflow that quietly becomes important to the team. This is healthy. People are finding real value on their own, faster than any official platform could have delivered it to them.
The problem is that bottom-up adoption creates a strange ownership gap. Work is getting done, but ask which agents touched the CRM last week, or what an agent read before it drafted that account report, and the honest answer at most companies is a shrug. The information exists — every run leaves a trail — but it sits in private chat histories and one-off automations nobody else can open.
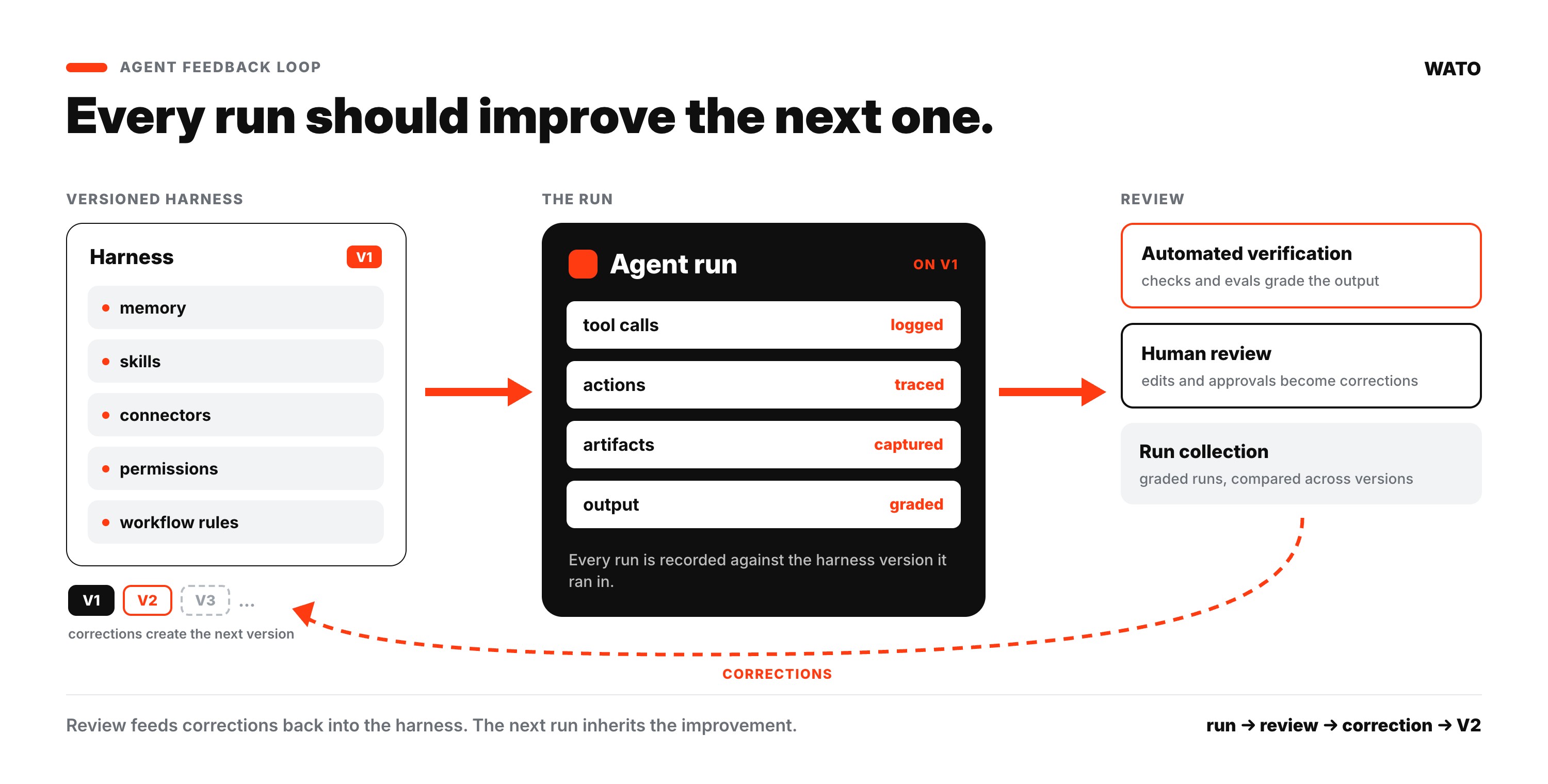
The instinctive fix is to give agents more context, and memory does help: an agent that knows the company makes fewer obvious mistakes. But memory is only one layer of something bigger that every company already has, whether it realizes it or not — a harness its agents run inside, made up of memory, tools, permissions, and workflow rules. Building that harness is half the job. The other half is a feedback loop, because the harness on its own cannot say whether an agent used it well. An agent with perfect context and no feedback repeats its mistakes forever; nothing records what went wrong or routes the correction back in. Agents become more reliable when the company can see how each run went and tune the harness in response.
The Useful Unit Is The Run
A run is the full story of one piece of agent work: what the agent was asked to do, what context and tools it used along the way, and how the result held up under review. Once a company can see that full path, failures become much easier to understand. A bad output is no longer a vague complaint about the model. It becomes an operational issue with a specific fix somewhere in the harness, and once the team makes that fix, every future run inherits it.
This is the shift companies need to make. They should stop treating agent output as isolated text and start treating agent runs as operational events. If an agent drafts a weak account brief, routes a request incorrectly, or produces a report that needs heavy editing, the important question is not just whether the answer was bad. The company needs to know why it was bad, and whether the failure came from the agent's context, its access, or the workflow itself. That is the difference between fixing one answer and fixing the system.
Corrections Should Improve The System
The most valuable feedback a company has is not a thumbs-up or a thumbs-down. It is the corrections people already make as part of normal work. When a manager rewrites an agent's customer follow-up, or an engineer fixes the stated root cause in an incident summary, they are showing the system exactly what good work looks like.
Today, those corrections usually improve a single output and nothing else. The person fixes the draft, ships it, and moves on. The company gets one better answer, but the system that produced the draft is unchanged, so the next agent makes the same mistake and someone has to apply the same judgment again by hand. A real feedback loop routes each correction into the harness instead of the artifact: stale information becomes a memory update, a wrong source becomes a workflow rule, and a failure that keeps recurring becomes an automated check. The correction stops being a one-time edit and becomes a permanent part of the environment every future run inherits.
A simple example makes this concrete. Suppose an agent is meant to summarize customer feedback from Slack, but it keeps searching too broadly and mixing internal chatter with real customer signal. The answer is not to keep reminding the agent to be more careful. The better fix is to change the workflow or tool parameters so the agent only searches the channels that matter, then save that as a new version. Future runs inherit the improvement, and the company can compare whether the new version performs better.
Run Collections Matter More Than Chat Histories
A chat history may show what someone said to an agent, but it usually does not capture the full environment that produced the work. A run collection ties agent work to a point-in-time version of the harness it ran in: the exact memory, skills, connectors, and permissions the agent had when it acted. When the company changes one of those layers, it can compare the next set of runs against the previous one and ask whether the system actually improved.
That is the enterprise version of a learning loop. It is not agents randomly exploring production systems in search of a reward. It is repeated company workflows, reviewed by humans and checked by automated verifiers, turning into a record of what worked and what did not. Every approval, rejection, and edit becomes a signal. Over time, those signals show the company where its agents are already reliable, where they need tighter boundaries, and which changes to the harness actually paid off.
Where Wato Fits
Wato is built around this loop. It is the harness for your organization's agents. It sits between AI clients and company systems, so teams can keep using the tools they already like while the company gets a shared, tunable environment for agents at work. Through Wato, an agent draws on reviewed team memory, follows versioned skills and workflows, and acts through approved connectors inside clear permission boundaries. Every run it performs lands in a run collection the company can inspect, tied to the exact version of the harness that produced it. That connection is the point: when a team changes the memory, a skill, or a permission, the next collection of runs shows whether the change made the work better.
The future of enterprise agents is not just bigger models with more context. The model is the one part of the system a company cannot control. The harness around it is the part it can, and tuning that harness is how agents actually get better: real work creates a record, review creates a grade, and corrections improve the next run. The first phase of AI adoption was about access: give people better tools and let them experiment. The next phase is about turning that scattered productivity into shared organizational learning. Once every useful run can make the next run cheaper, safer, or more effective, agents stop being one-off assistants and start becoming part of a company system that improves with use.